Breaking VAE
This blog assumes Jesse knows basics of linear algebra and probability :)
Jesse: Yo Mr. White, I'm hearing a lot about this diffusion thing in the hood yo, like it's the shit man! I've seen people learning about VAE first when they are getting started with this. I also want to learn about this yo, teach me!
W. White: Yeah, I've heard about that too. Alright, I can teach you about VAE but things can get a little tricky.
Jesse: I ain't a pussy yo, test me!

W. White: Alright alright! Before we get on to VAE, you need to know about Auto Encoder first. It is a combination of encoder and a decoder, where the encoder encodes the input data to some compressed code , and the decoder decodes to get a similar reconstruction of the input data. But this has one issue, that is, this is not able to capture the semantic relationship between the data. I mean how can an airplane and a human share the same code!?
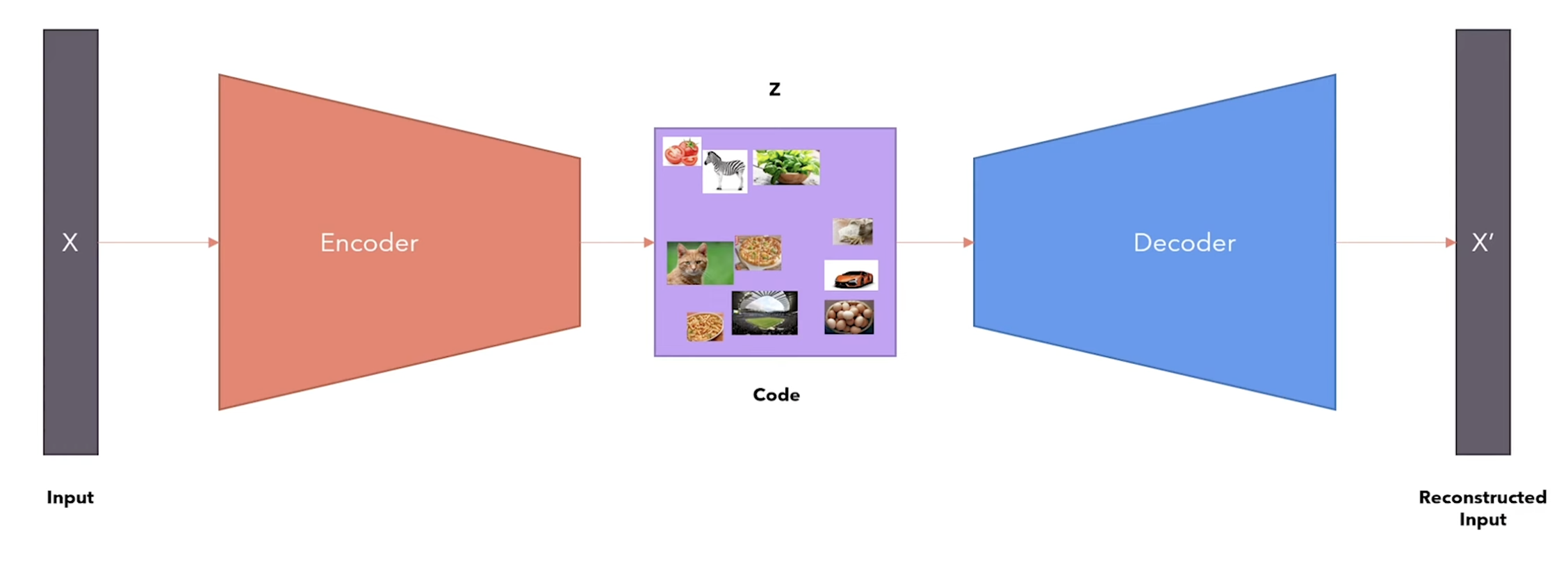
from the Variational Autoencoder video by Umar Jamil
Jesse: Right on yo! Ok so what's the solution to this issue? Like we convert the human into an airplane type shi?!
W. White: Well no, we take care of it by learning a latent space. The latent space represents the parameters of the multivariate distribution over the data (mean, variance), and is much simpler than the distribution of the original input data. The advantage of this is that if your data has let's say faces of different humans, they will end up being closer to each other in the latent space and away from other type of data, capturing the semantic relationship between the data.
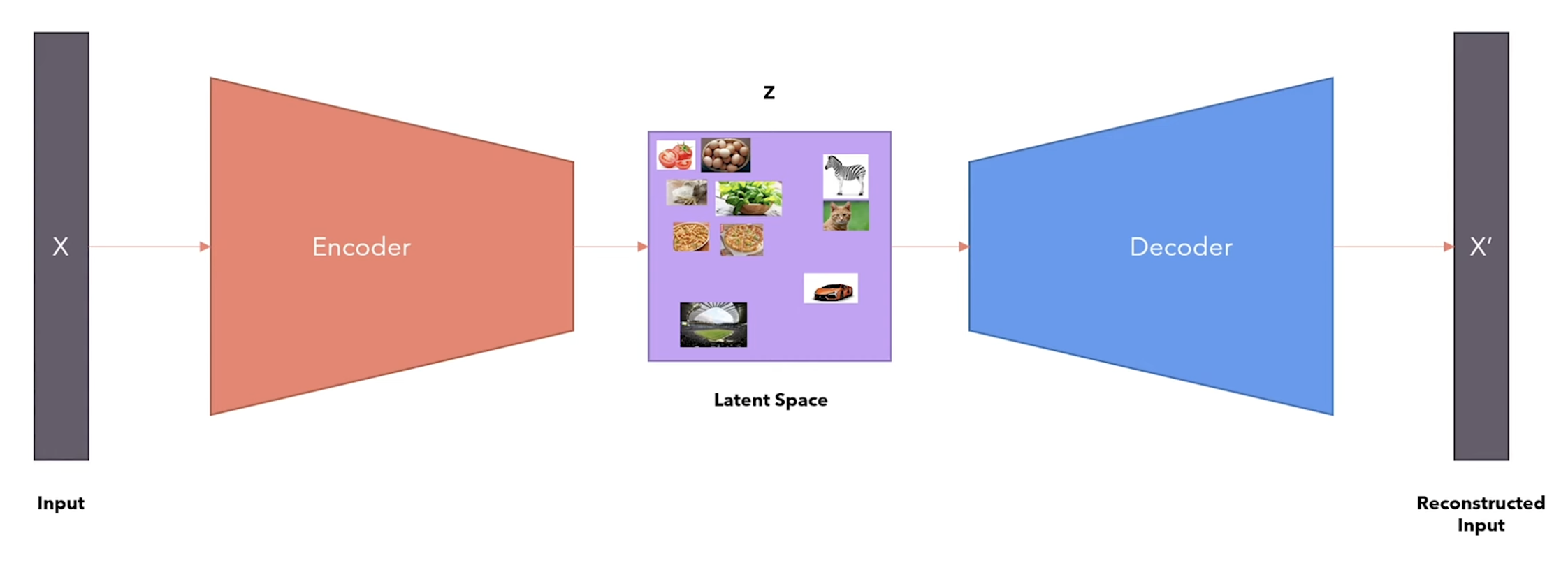
from the Variational Autoencoder video by Umar Jamil
Jesse: Damn I see, how did they even think of this shit!? Anyways, how do we get this thing running? like how do we train it to actually work? I can't wait to run this tonight baby!
W. White: Hold your horses Pinkman, so now our goal here is to maximize the likelihood of the distribution of the data after being decoded by the decoder. By the law of total probability, we can write it as:
Now, this is intractable as we have to integrate it over all the values which we don't know yet. If we try with Bayes rule:
is also intractable as computing in the denominator requires integrating over all again, bringing us right back to the intractable integral we started with.
Jesse: Dang no wayy, sooo what do we do here Mr. White? This can't be it right? Like there's has to be a way around this!?
W. White: Well, to get around this problem, we introduce an approximate posterior that is assumed to be tractable and is an approximation of the true posterior .
Jesse: Aha, like an alternative right?!

W. White: Yes, something like that, now can you just shut up and listen to what I'm saying!? Now when we try to maximize the log likelihood of the distribution , we can write it as:
(expectation over a constant is constant itself)
and then we do some maths like replacing the term using Bayes Rule, multiplying and dividing with the same thing and then write it as a summation of these 2 terms — the ELBO and the KL divergence between the approximate posterior and the true posterior.
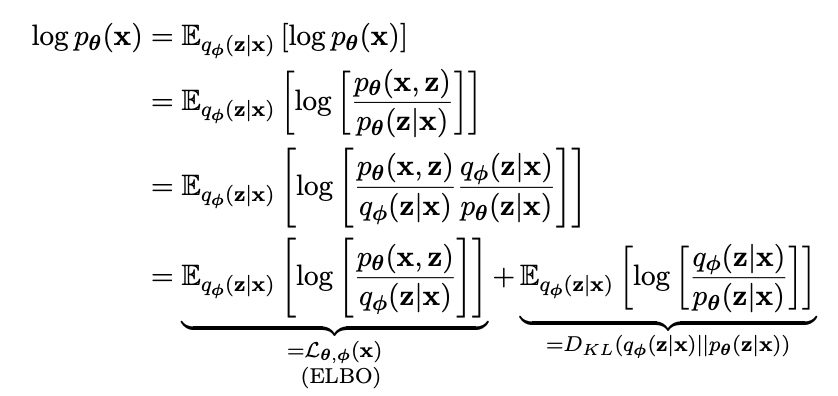
on page 18 of An Introduction To Variational AutoEncoders book
Jesse: Woah woah, hold on, too much at once. Umm so, what is an ELBO? Can I seriously hit you in the face with that!? And what the fuck is KL Divergence?
W. White: So, ELBO, which is Evidence Lower Bound, is the lower bound of the log likelihood of the distribution and KL Divergence is a way to calculate the difference between 2 distributions. Now, as KL Divergence cannot be negative, it is always , which means:
hence ELBO serving as the lower bound for the log likelihood.
Jesse: Right on, Mr. White! So, if we keep the ELBO up, it keeps the likelihood up as well! That's our goal right?
W. White: Exactly, I didn't expect you to be smart but yes.

W. White: So, our goal becomes to maximize the ELBO now. And to maximize it, we can simply use SGD. But, you know, there's a problem here. The original VAE paper mentions that it is impractical to run the estimator on this expectation over our stochastic latent space as it just has very high variance and god knows if it will converge.
We need a way to outsource the randomness of the latent space so that we can actually learn the parameters of the model. For this, we introduce the "reparameterization trick", where we now sample using the mean, variance and some external noise :
This trick helps in backpropagation, to learn the mean and variance of the latent space as the randomness now comes from the external noise.
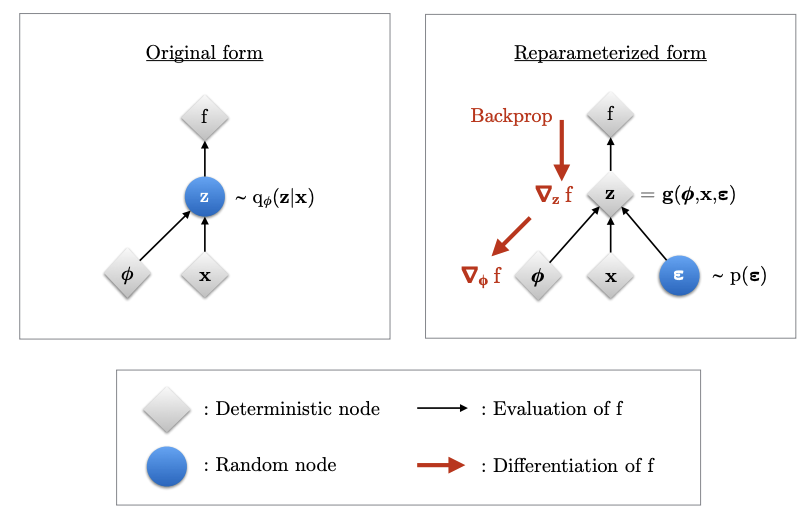
on page 22 of An Introduction To Variational AutoEncoders book
Jesse: Oh, this helps Pytorch with the backprop thing right...
W. White: Since when did you know about Pytorch!? I thought you only knew about cooking and that too a shit product?
Jesse: I ain't an addict anymore yo! I'm exploring stuff you know like this and museums with paintings that apparently look like vaginas ..
W. White: Well, good for you. Anyways, so after this trick, the new estimator has less variance than the previous one. Now, as we can finally use SGD (stochastic gradient descent), let's also talk about the loss function that we have to minimize. We'll not go over the derivation of it, it's just too complicated to be explained right now.
fun fact: the author of this blog has no clue about the derivation either :)
W. White: So, in the original VAE paper, the loss function boils down to these 2 terms, first one being the KL Divergence between the prior distribution (what we want our space to look like, we take Gaussian distribution for simplicity) and the distribution learned by the model. The second term is just the reconstruction loss which is MSE (Mean Squared Error) between the input data and the reconstruction of that data as we assume our decoder to be Gaussian.

on page 5 of Auto-Encoding Variational Bayes paper
W. White: And there you have it, you train your model to minimize this loss and you'll get yourself a simple latent space that represents your data distribution.
Jesse: Right on baby! Gotta say Mr. White, you're one hell of a teacher. But Mr. White, I've observed that the reconstruction from the VAE are generally blurry, why's that?
W. White: Thank you for your kind words, it's rare to hear them from the mouth of an addict and yes, that's a nice question. It happens because the MSE tends to average over the distribution, producing blurry outputs. This is what is solved by the diffusion and GAN models, but that's a whole other story for another time. I'm pretty sure you won't get the whole thing from just one conversation, I'll tell you some good resources you can refer to learn more about VAE.
Jesse: That'll be great actually, but don't tell any of your own books though. I've had enough of you already.
W. White: Yeah yeah whatever. These resources do a really good job explaining VAE:
- Variational Autoencoder - Model, ELBO, loss function and maths explained easily!
- An Introduction To Variational AutoEncoders
- Auto-Encoding Variational Bayes (original VAE paper)
Jesse: Alright, thanks Mr. White, appreciate it. I'll bounce now, got some stuff to do at home...
W. White: You?? And Work?? Am I hearing this right? Is this a dream or something?!
Jesse: Yeah, got responsibilities you know ;)

editor note: Why did I write this blog on a seemingly complex topic as a conversation between 2 characters from Breaking Bad? Well, I've been watching Breaking Bad lately and also started learning about diffusion models and I thought it'll be fun to, you know, mix both of them up, and hence this thing was born :) I hope you liked it <3, feel free to reach out to talk more about it or maybe criticize it, everything is welcome.